AI 合规与隐私保护:人工智能技术应用中的合规风险
发布时间:2025-05-16 10:42:30
在人工智能(AI)技术飞速发展的当下,AI 已广泛融入人们生活的各个角落,从智能语音助手到个性化推荐系统,从图像生成软件到智能医疗诊断工具,其带来的便利与创新不言而喻。然而,AI 技术在带来便利的同时,也对个人信息保护与隐私安全构成挑战。本文从训练数据、生成内容 服务过程三大维度,结合相关个人信息保护法律与可能出现的场景,解析 AI 技术应用中个人信息保护的合规挑战和治理盲区。
一、训练数据:个人信息的 “源头性” 合规隐患
AI 模型的训练依赖于海量的数据,其中不乏包含个人信息的语料。例如,某聊天机器人训练数据中可能包含用户历史对话、搜索记录,甚至医疗、金融等敏感信息。《生成式人工智能服务管理暂行办法》明确规定,涉及个人信息的训练数据 “应当取得个人同意或者符合法律、行政法规规定的其他情形”,但实践中仍存在多个合规挑战:
1.数据来源合法性
在通过爬虫技术抓取公开网页信息时,如果缺乏对信息类型的有效甄别机制,会导致公开信息中混杂的个人信息被不当采集。例如,社交媒体用户发布的图文内容、论坛留言、公开简历等,虽属于平台展示的公开信息范畴,但其中可能包含姓名、联系方式、健康状况、行踪轨迹等具有个人身份识别性的信息。

场景:某电商平台开发智能客服机器人时,通过爬虫抓取行业论坛公开帖子,未过滤用户留言中包含的手机号、收货地址等信息,导致用户咨询记录中的个人信息被批量纳入训练数据。
法律依据:违反《个人信息保护法》第 27 条(处理已公开个人信息未合理评估对用户权益的影响,且未采取去标识化处理)。
2.敏感数据处理
生物特征(人脸、声纹)、医疗记录等敏感信息若未经过脱敏处理,可能在模型生成内容中泄露,有的虽进行脱敏处理,却仅停留在形式层面,保留了如特定症状与就诊时间组合等可推断个人身份的间接信息,导致模型生成内容时可能通过上下文关联泄露用户隐私。

场景:某健康管理 APP 开发疾病预测模型时,直接使用含患者姓名、就诊日期、病症描述的原始医疗数据进行训练,仅删除身份证号字段,未对 “病症 + 就诊医院 + 时间” 等可推断身份的组合信息进行脱敏,导致模型输出时关联泄露用户就医隐私。
法律依据:违反《个人信息保护法》第 29 条(处理敏感个人信息未取得单独同意,且未进行充分去标识化)。
3.跨境数据流动
境外训练数据包含中国用户个人信息时,需依《数据安全法》履行出境评估义务。但部分主体未筛查敏感数据,或规避评估直接传输至境外,导致用户信息面临存储安全风险、监管脱节及维权障碍。
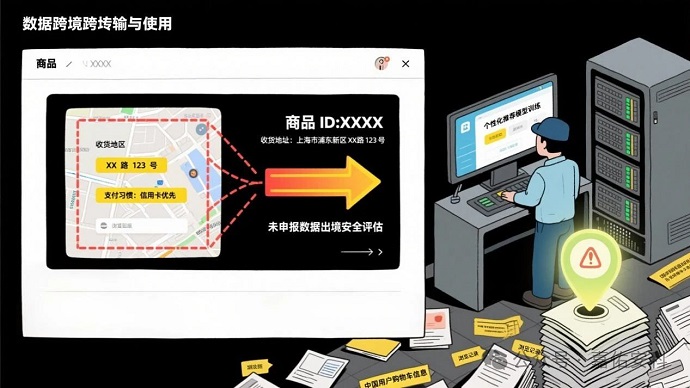
场景:某跨国企业将中国用户的购物车信息、浏览记录传输至境外服务器用于个性化推荐模型训练,未向国家网信部门申报数据出境安全评估,且未对其中包含的收货地址、支付习惯等数据进行本地化处理。
法律依据:违反《网络安全法》第 37条(重要数据出境未履行安全评估义务)。
二、生成内容:隐私侵害的 “间接性” 传导风险
AI 生成的文本、图像、视频等内容虽不直接抓取或存储个人信息,却可能通过 内容关联、身份伪造、社会信任破坏等路径,成为隐私泄露与权益侵害的间接载体。
1.身份伪造风险
深度合成技术可生成逼真的 “人脸替换” 视频、“声音克隆” 音频,未经授权使用他人生物特征即构成对肖像权、声音权的侵害。

场景:某服装品牌未经允许,利用深度合成技术将明星王某的面部特征和声音植入素人模特视频,制作成 "王某同款穿搭" 广告在电商平台发布。视频中模特的表情、语气与王某高度相似,且未标注 “AI 生成” 标识,误导消费者认为其为品牌代言人。
法律依据:违反《互联网信息服务深度合成管理规定》第 17 条(未对人脸合成内容进行显著标识)与《民法典》第1019条(未经允许侵犯他人肖像权)。
2.信息误导风险
生成式 AI 若基于含偏见的训练数据,可能输出包含性别歧视、地域歧视的内容,间接侵害特定群体的人格权益。

场景:某招聘平台算法因训练数据中男性从业者简历占比过高,在筛选 “技术岗位” 时自动降低女性求职者的匹配分值,导致女性候选人获得面试邀请的概率显著低于男性。
法律依据:违反《互联网信息服务算法推荐管理规定》第 21 条(算法在交易条件上实施不合理的差别待遇)。
3.交互数据留存
部分 AI 服务提供者非法留存用户输入的问题或对话记录,导致聊天内容、搜索偏好等隐私信息被滥用。

场景:某智能问答机器人在用户咨询 “投资理财” 时,未经明确告知擅自留存对话内容及用户输入的资产规模、风险偏好等信息,并将其用于第三方金融机构的精准营销推送。
法律依据:违反《个人信息保护法》第 23条(未征得用户同意留存交互数据,且超出约定用途使用)。
三、服务过程:用户权益保障的 “象征性” 责任缺失
用户在使用生成式人工智能服务时,用户的法定权利因技术不透明性与制度性缺陷的交互作用,呈现出权利保障的形式化剥离现象
1.知情同意流于形式
隐私政策与服务协议中关于 “数据收集范围”“用途” 的表述晦涩,用户难以真正理解个人信息如何被使用。

场景:某教育类 AI 题库在用户注册时,隐私政策中收集个人信息目的仅用改善服务质量、提示用户为由,“司法管辖区服务器”“去标识化”等专业术语,普通用户难以理解其含义。
法律依据:违反《个人信息保护法》第 17 条(未清晰、完整告知数据处理目的与范围)。
2.数据控制权缺失
用户缺乏便捷渠道查阅、更正或删除 AI 系统中存储的个人信息,部分平台甚至拒绝用户的删除请求。

场景:用户要求某短视频平台删除其历史搜索记录,平台以 “数据存储系统无法单独删除该字段” 为由拒绝,且未提供替代解决方案,导致用户无法行使数据删除权。
法律依据:违反《个人信息保护法》第 47 条(未履行用户数据删除权义务)。
3.未成年人保护薄弱
针对青少年的 AI 学习工具可能过度收集学习习惯、社交关系等数据,且未设置防沉迷或隐私保护机制。

场景:某儿童编程学习 APP 在未征得监护人同意的情况下,收集 7-12 岁用户的课堂互动语音、作业提交记录、社交好友列表等数据,且未设置数据访问权限与使用时长限制。
法律依据:违反《个人信息保护法》第31条和《未成年人保护法》第 72 条(未征得监护人同意收集儿童语音、社交数据,且未制定专门处理规则)
结语
AI 技术应用中的隐私风险贯穿训练数据、生成内容及服务过程,对合规治理提出多维度挑战。应对这一问题,可以以法律框架为基准,构建覆盖数据采集、内容生成、权益保障的治理路径:强化训练数据合法性审查与去标识化,从源头防控敏感信息滥用;推进生成内容标识追溯技术,提升信息透明度;完善用户权利响应机制,保障数据控制权。通过法律规制、技术手段与伦理协同,推动企业主动合规,促使技术创新与隐私安全动态平衡,为数字时代构建兼具活力与信任的治理生态。
